Nested List Processing
As we have learned previously in this blog, Haskell is a language where lists are very important and therefore unsurprisingly one of the most important issues that must be addressed when programming in Haskell is how exactly are operations applied to lists?
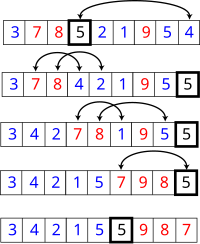
In order to see if we can find some of the issues with operations on lists, let's write a quick maximum function that takes a list and returns the max value of the list.

This is a pretty standard way to do this in Haskell, let's take a closer look about how it works.
Fist we must import the Data.List library
Next we can define a function and give it a type definition.
The first line of actual code reads:
maximum':: (Ord a) => [a] -> a
The next line simply takes the element of the list and sets it to the Lambda Variable x
Finally the line maximum' (x:xs) = max x (maximum' xs)starts at the head of the list and recursively goes through and finds the maximum value in the list.
So far this is nothing we haven't already done in this blog and so we can expect to have success in our simple maximum function. Here are a few examples:


And again nothing really surprising here.
So where does the problem come in? Consider this, what if we had a list of lists and I wanted to find the biggest value in the entire collection? What would I happen if I just gave our regular function a list of lists? Let's see!
So here is the same function with a list of lists being passed in, rather than a list of simple integers:

So what we would want to happen is have the function return a value of 11. This is the result when this method is run:

Shoot! That's not quite what we were expecting. Why was a list returned instead of a single integer? The way this method is currently written can not handle nested lists. It simply finds the list with the greatest number of elements instead of the highest value from any list. How can we modify this?
In Haskell a pretty popular way to handle these lists is to flatten them. This is done by using a method within the standard Data.List library called intercalate. This method takes a list of lists and flattens it down to one list. Here is how I decided to implement this in Haskell:
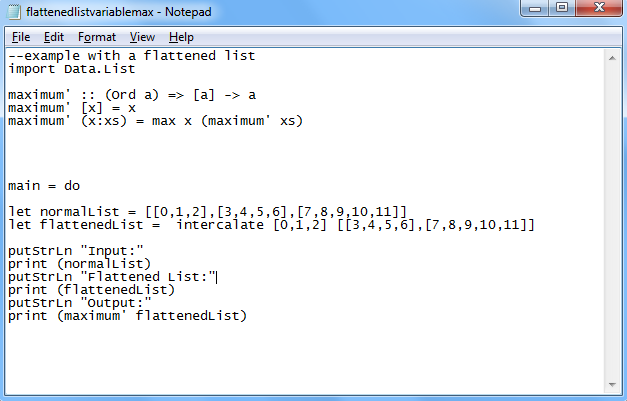
And here is the result:

Now we can observe the result of 11 that we might have expected from the first method. This begs the question, which is a better way to handle lists? Well that depends if you have nested list values and you want a simple maximum of any element in any list or sub-list then the method using flattening is the correct way to do it. However if you have data and you want to know which list has the most elements in it the first way with a non-flattened list of lists would be the correct approach.
I hope you had as much fun reading this blog as I had writing it.
That's all for now.